chat_voice插件
目录
建议配合视频使用
本教程为尽可能地简化部署流程,降低部署难度,特意提供了项目所需的python包(内含所需依赖)和chat_voice包(已经对内容进行了修改)
前提:已经安装了QChatGPT和mirai,没有安装的请根据部署教程自行安装
准备工作
使用Huggingface的在线语音生成
注意: Huggingface永久免费但每次限制150字
首先注册一个Huggingface的账户,点击跳转注册 点击这个链接:https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer 在仓库右上角,点击三个点,选择Duplicate this Space(复制空间) 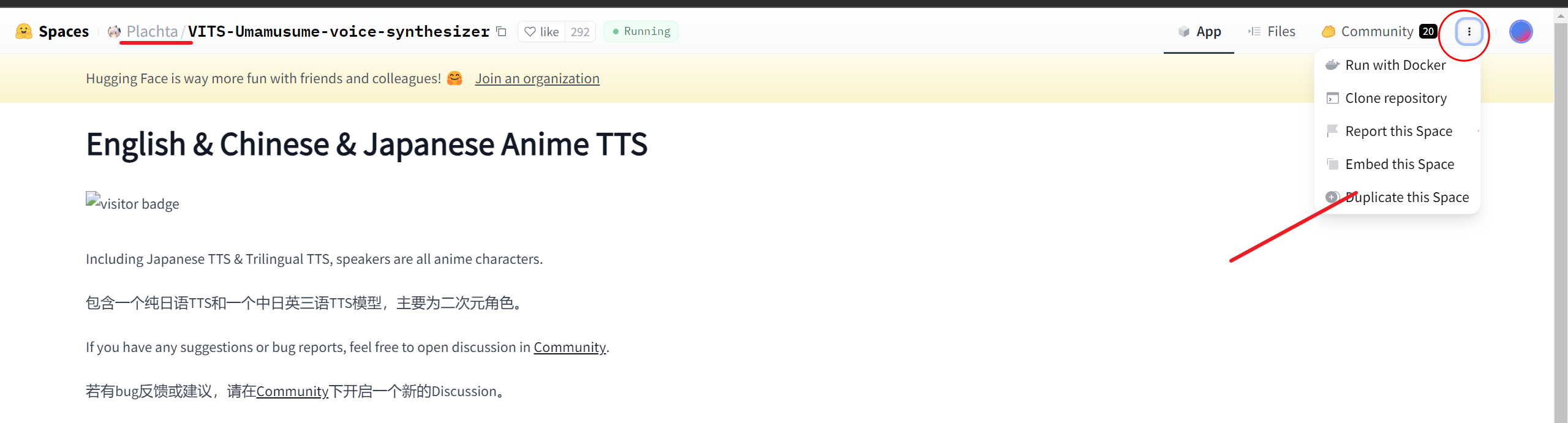 选择公有库Public,私有库会导致连不上,然后点击Duplicate Space
选择公有库Public,私有库会导致连不上,然后点击Duplicate Space 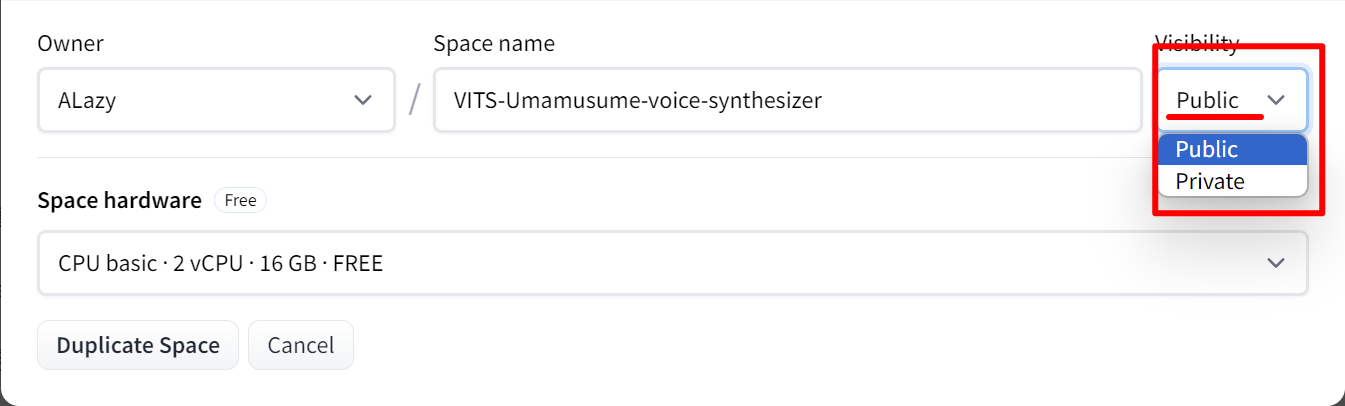 等待空间创建完毕 打开开发者工具(F12),在工具栏中选择网络,随便选择一个模型(这里的选择应该不会影响的你之后使用Huggingface生成音频时的音色),如图
等待空间创建完毕 打开开发者工具(F12),在工具栏中选择网络,随便选择一个模型(这里的选择应该不会影响的你之后使用Huggingface生成音频时的音色),如图 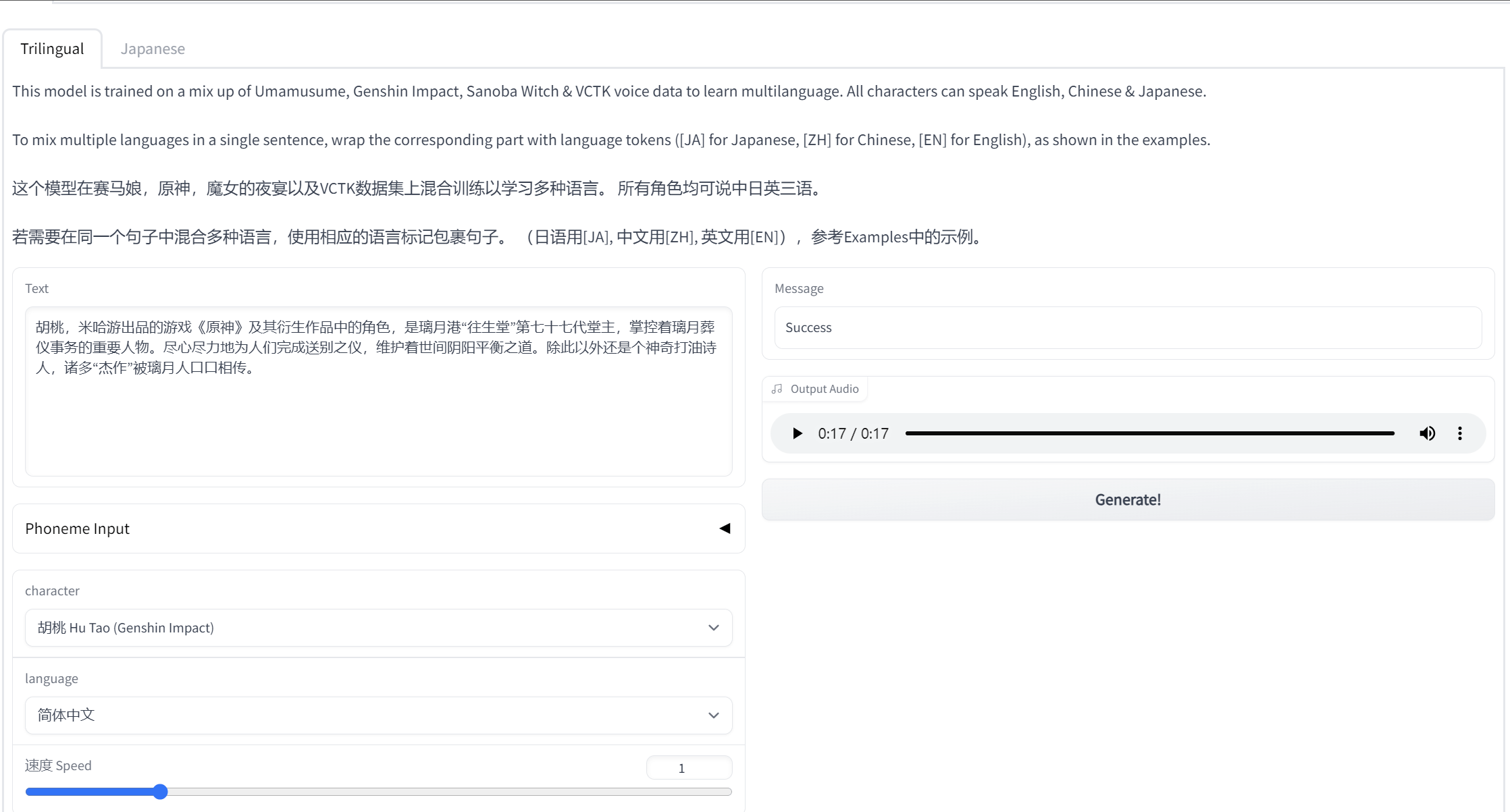 点击Generate生成一个音频 观察到网络(Network)控制台有一个join包,如图。点击后会出现的websocket链接(以wss开头),复制下来
点击Generate生成一个音频 观察到网络(Network)控制台有一个join包,如图。点击后会出现的websocket链接(以wss开头),复制下来 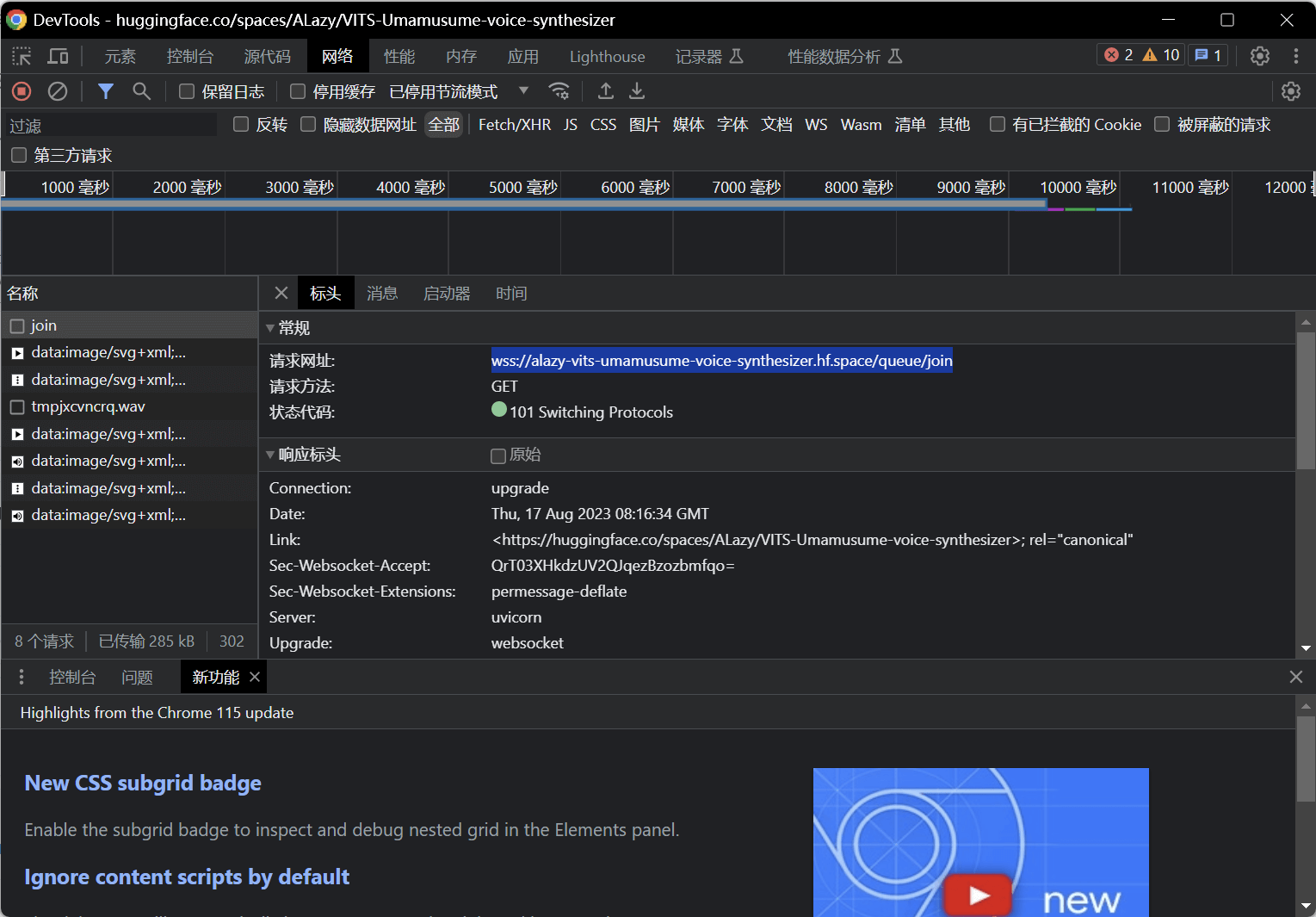 将生成的音频点击播放一下 这时观察网络控制台多出来一个wav文件,如图。将链接复制下来,并去掉file=后面的参数 例如:
将生成的音频点击播放一下 这时观察网络控制台多出来一个wav文件,如图。将链接复制下来,并去掉file=后面的参数 例如:/tmp/tmptdrqcg0g/tmpjxcvncrq.wav,留下的链接形式应该是这样的:https://alazy-vits-umamusume-voice-synthesizer.hf.space/file=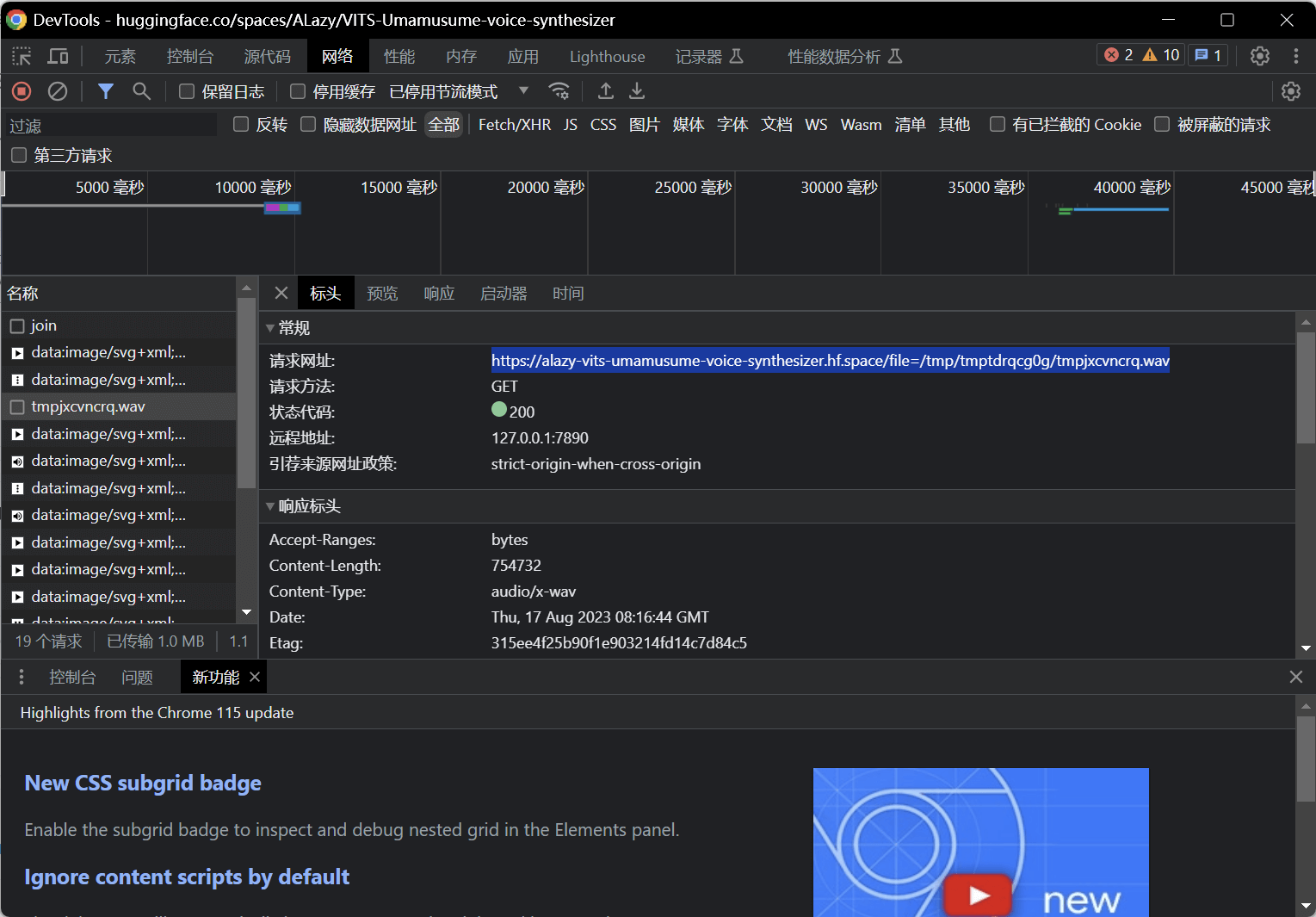
使用Azure的在线语音生成
注意: Azure不是永久免费,但每月50万字的免费体验额度
首先在Azure注册账号,点击注册
注意:Azure的免费语音生成需要使用外币卡验证
然后在Azure创建语音服务,点击跳转 按要求填写好信息后点击审阅并创建,再次点击创建 创建完成后,点击转到资源,找到下方的密钥(1和2任选一个)和Location/Region,将两个内容复制下来
安装并修改配置文件
手动安装部署
打开这个网页: https://github.com/oliverkirk-sudo/chat_voice 点击右上绿色图标CODE,点击Download ZIP,如图 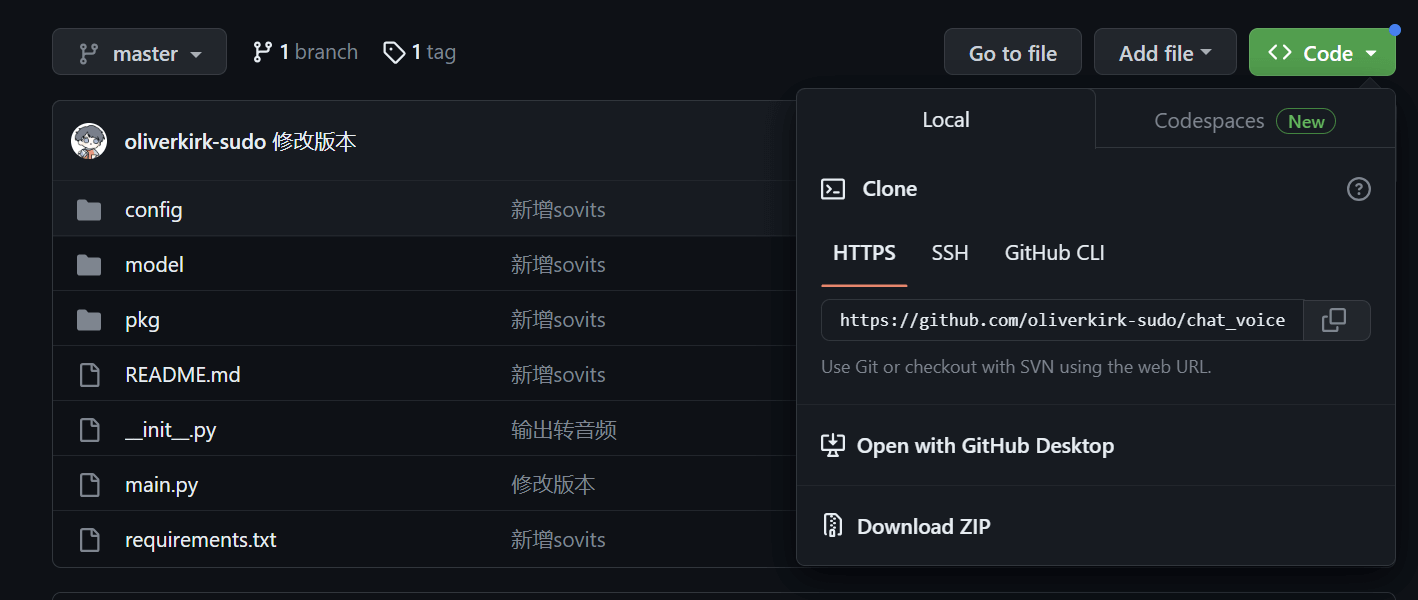 将下载的压缩包解压,得到如图文件夹,将文件夹名字修改为
将下载的压缩包解压,得到如图文件夹,将文件夹名字修改为chat_voice 将修改后的
将修改后的chat_voice文件夹移动到QChatGPT\plugins文件夹内,如图 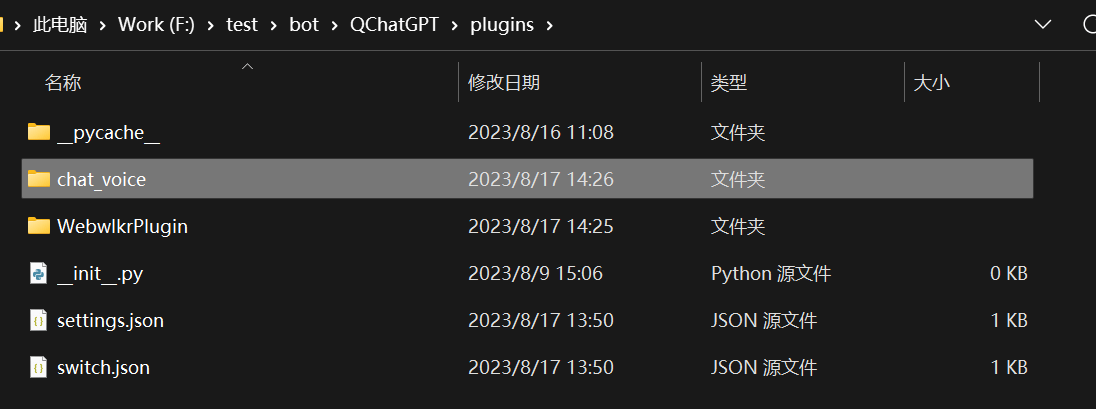 打开
打开chat_voice文件夹,双击打开requirements.txt文件,把里面的内容修改为以下(直接删除里面的,把下面的复制进去)
azure-cognitiveservices-speech~=1.26.0
websocket-client~=1.5.1
av~=10.0.0
pilk~=0.2.3
librosa~=0.10.0.post2
torch
torchvision
torchaudio
torchcrepe
Ctrl+S保存后,打开同目录的config文件夹,找到mapper.py文件,如图 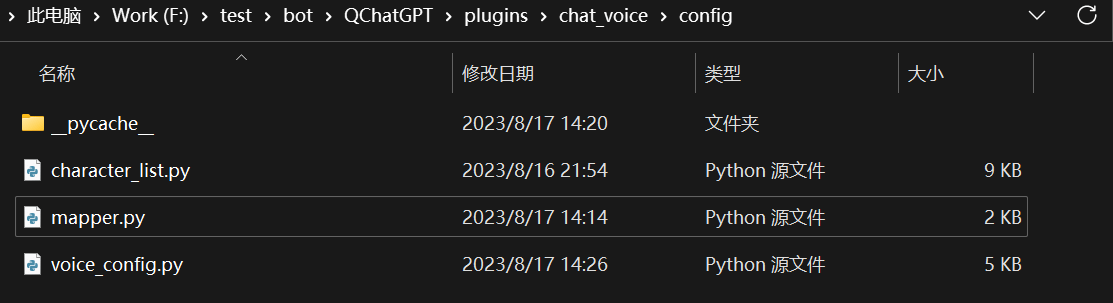 修改
修改mapper.py文件(使用如VScode的代码编辑器或记事本),把里面的内容修改为以下(直接删除里面的,把下面的复制进去)
import logging
import traceback
from plugins.chat_voice.config.voice_config import SoVitsConfig
method_mapping = {
# 'azure': save_azure_wav,
# 'huggingface': get_audio_wav,
# 'vits': save_vits_wav,
# 'sovits': save_sovits_wav
}
voice_type_mapping = {
# 'azu': 'azure',
# 'hgf': 'huggingface',
# 'vits': 'vits',
# 'sovits': 'sovits'
}
sovits_model=''
try:
from plugins.chat_voice.config.voice_config import voice_config,azure_config,huggingface_config,vits_config,SoVitsConfig
except Exception:
logging.error("请正确配置voice_config.py")
traceback.print_exc()
try:
if huggingface_config['open']:
from plugins.chat_voice.pkg.huggingface.huggingface_session_hash import get_audio_wav
method_mapping['huggingface'] = get_audio_wav
voice_type_mapping['hgf'] = 'huggingface'
if azure_config['open']:
from plugins.chat_voice.pkg.azure.azure_text_to_speech import save_azure_wav
method_mapping['azure'] = save_azure_wav
voice_type_mapping['azu'] = 'azure'
# if vits_config['open']:
# from plugins.chat_voice.pkg.vits.vits_text_to_speech import save_vits_wav
# method_mapping['vits'] = save_vits_wav
# voice_type_mapping['vits'] = 'vits'
# if SoVitsConfig().OPEN:
# sovits_config=SoVitsConfig()
# from plugins.chat_voice.pkg.sovits.sovits_text_to_speech import save_sovits_wav,modelAnalysis
# method_mapping['sovits'] = save_sovits_wav
# voice_type_mapping['sovits'] = 'sovits'
# sovits_model=modelAnalysis(sovits_config.MODEL_PATH, sovits_config.CONFIG_PATH, sovits_config.CLUSTER_MODEL_PATH, sovits_config.ENHANCE, sovits_config.DIFF_MODEL_PATH,sovits_config.DIFF_CONFIG_PATH, sovits_config.ONLY_DIFFUSION)
except Exception:
logging.error("包加载错误")
traceback.print_exc()
Ctrl+S保存并关闭
再打开voice_config_temp.py文件,按照注释填写 你需要重点关注的就是 azure_config下的"region"和"secret"huggingface_config下的"download_url"和"websocket" 并把vits_config下的open: True改为open: False 如果没有Azure的语音生成服务,可以把默认生成模型改为Huggingface,例如 "voice_type": "azure"改为"voice_type": "huggingface" 其他特殊要求请按注释更改 没有更改后,Ctrl+S保存并关闭,并将文件名voice_config_temp.py改为voice_config.py
下面开始安装插件所需依赖,这里提供两种方式:
- 方式一:推荐新人使用,通过我提供的一个脚本自动一键安装,适合使用自动安装器部署QChatGPT项目的人
脚本下载:点我下载
将它保存在chat_voice目录,双击运行 程序即可自动加载,安装所需依赖(正是requirements.txt里面写的依赖) 运行到下面这样子时就安装成功了(黄字提醒不重要),如图 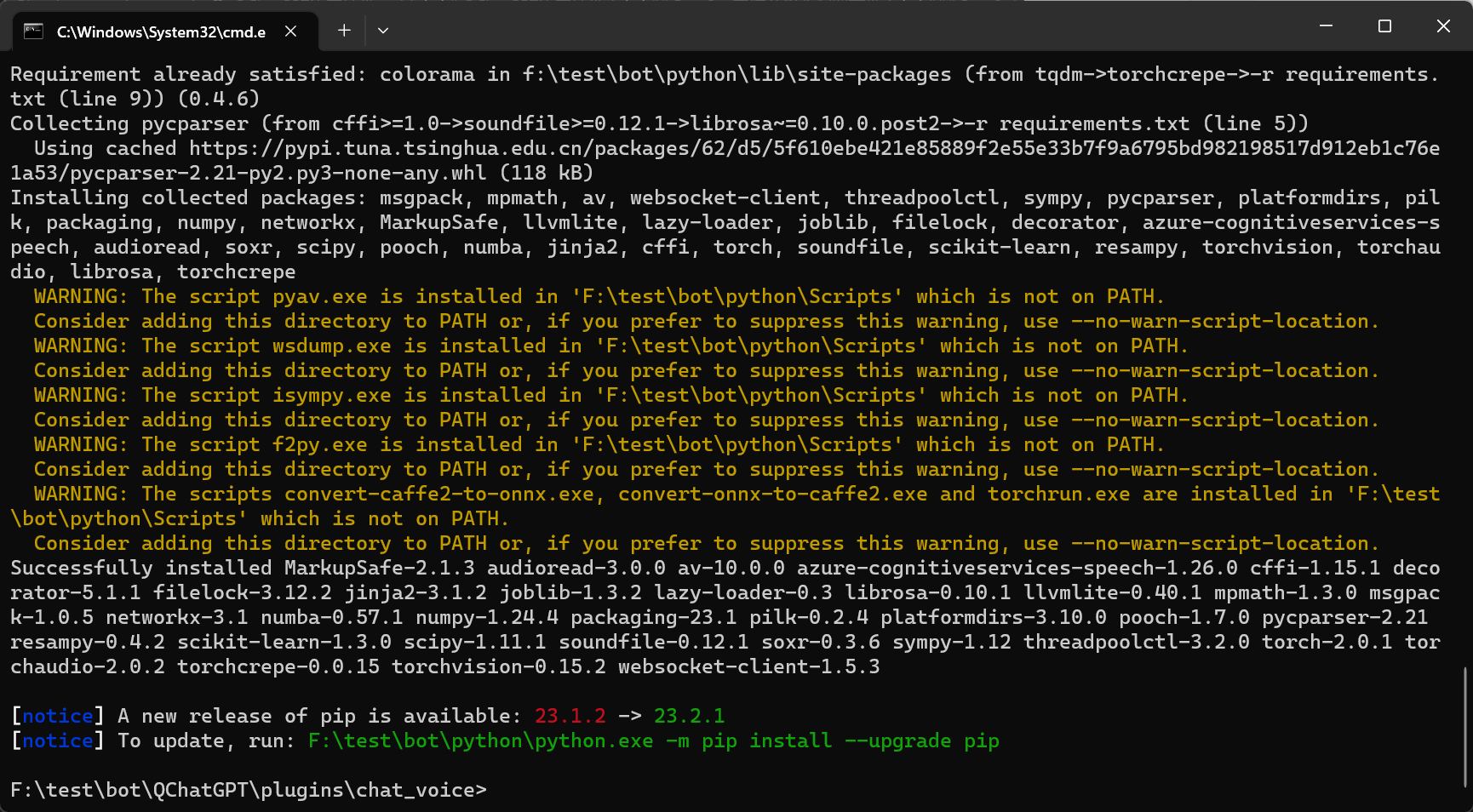 然后运行
然后运行run-mirai.bat和run-bot.bat
- 方式二:通过手动安装,适合想要多了解有关操作的人 然后返回的上级
chat_voice目录,可以看到有一个requirements.txt文件 这时,再打开项目根目录(就是QChatGPT文件夹的同目录),可以看到python文件夹,如图 打开
打开python\Scripts文件夹,可以看到pip.exe文件,如图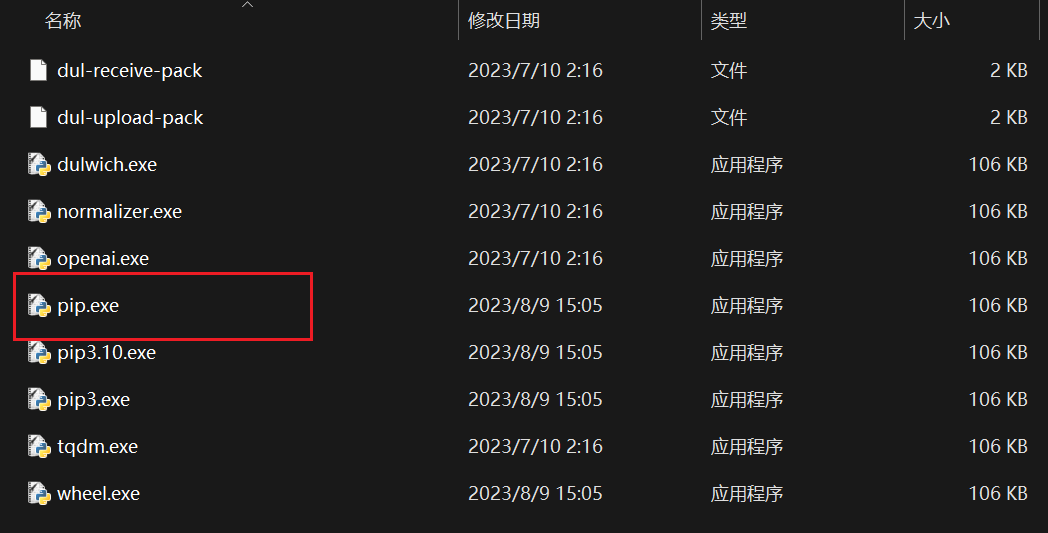 然后右击文件,复制
然后右击文件,复制pip.exe的路径,你将得到一个大致这样的路径"F:\test\bot\python\Scripts\pip.exe"(F:\test\bot\取决于你放的位置和文件夹起名),这时再把双引号去除后复制一遍,防止双引号未去除给后面的操作带来影响 然后在chat_voice文件夹的上方地址栏,光标移动到路径最前面后,输入cmd和一个空格(不是输入汉字,是按一下空格),如图 回车就可以看到在当前位置打开了命令提示符,如图
回车就可以看到在当前位置打开了命令提示符,如图 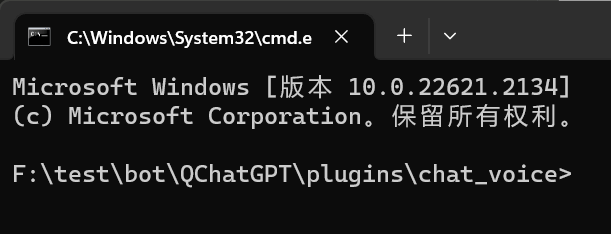
在cmd窗口输入以下命令,其中F:\test\bot\python\Scripts\pip.exe替换为你刚才复制的路径
Tips:
-r表示表示遍历,-i表示选择使用的镜像,-i后面的链接即为镜像源
F:\test\bot\python\Scripts\pip.exe install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
输入完成确定无误后回车,即可自动安装所需依赖(正是requirements.txt里面写的依赖) 运行到下面这样子时就安装成功了(黄字提醒不重要),如图
使用压缩包部署
压缩包使用百度网盘分享,网盘提取码获取方式: 三连关注后私信UP主,发送chat_voice或4,将会自动回复提取码
压缩包使用方法: 下载好python压缩包后,移动到项目文件夹根目录,并解压到当前位置,如图 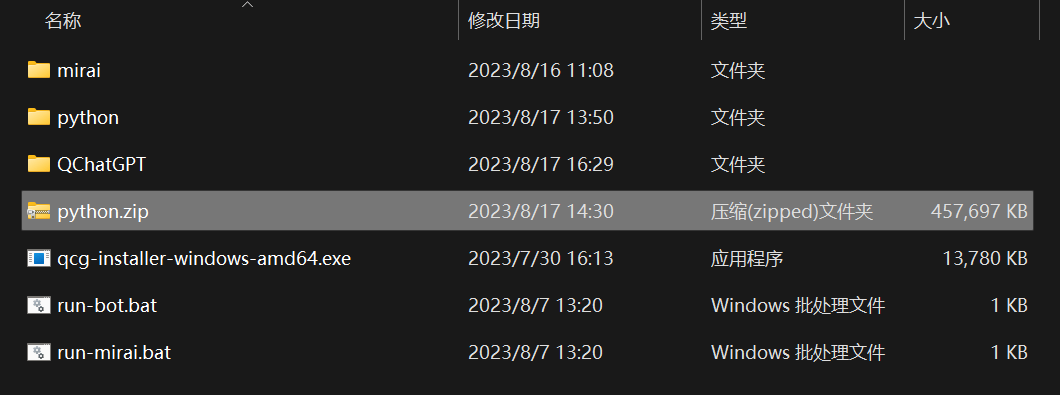 下载好chat_voice压缩包后,移动到
下载好chat_voice压缩包后,移动到QChatGPT\plugins文件夹下,并解压到当前位置,如图
然后修改chat_voice\config文件夹下的voice_config.py,按照注释填写 你需要重点关注的就是 azure_config下的"region"和"secret"huggingface_config下的"download_url"和"websocket" 如果没有Azure的语音生成服务,可以把默认生成模型改为Huggingface,例如 "voice_type": "azure"改为"voice_type": "huggingface" 其他特殊要求请按注释更改 没有更改后,Ctrl+S保存并关闭 然后运行run-mirai.bat和run-bot.bat
使用方法
注意: 需要使用全局代理,或在QChatGPT\plugins\chat_voice\config的voice_config.py文件中配置代理(使用时去掉#注释,并正确配置)
# "proxy_host": "127.0.0.1", #代理ip
# "proxy_port": 7890, #代理端口
# "proxy_type": "http" #代理方式 http | socks5
包含的指令:
!voice on开启输出转语音!voice off关闭输出转语音!voice type azu切换Azure语音合成!voice type hgf切换Huggingface语音合成!voice type vist切换VITS语音合成!voice type sovist切换VITS语音合成tovoice 文本内容将文本内容转换为语音消息
以上指令请以管理员身份向机器人发送